OneThingAI上新9款模型,解锁AI应用新可能
当现实中的信息更多以直观复杂的图像、图表、视频形式呈现(而非文字)时,传统AI模型的文字依赖特性逐渐难以满足用户需求。鉴此,在日前发布的OneThingAI模型API服务基础上,网心科技今天再次上线了9款主流视觉语言模型,不仅能够实现对图像与视频画面的智能解析,更能通过逻辑推理来解决复杂问题或提供决策参考。
OneThingAI模型API服务
本次上线的模型包含:
通义千问 Qwen3系列
采用混合专家(MoE)架构,支持119 种语言,可灵活切换「快思考」与「慢思考」模式。在多个权威基准测试中,Qwen3在通用对话、数学推理、代码生成等多个高难度、关键性指标上取得了极高分数,展现了其强大的综合能力,无疑是当前开源模型的第一梯队。
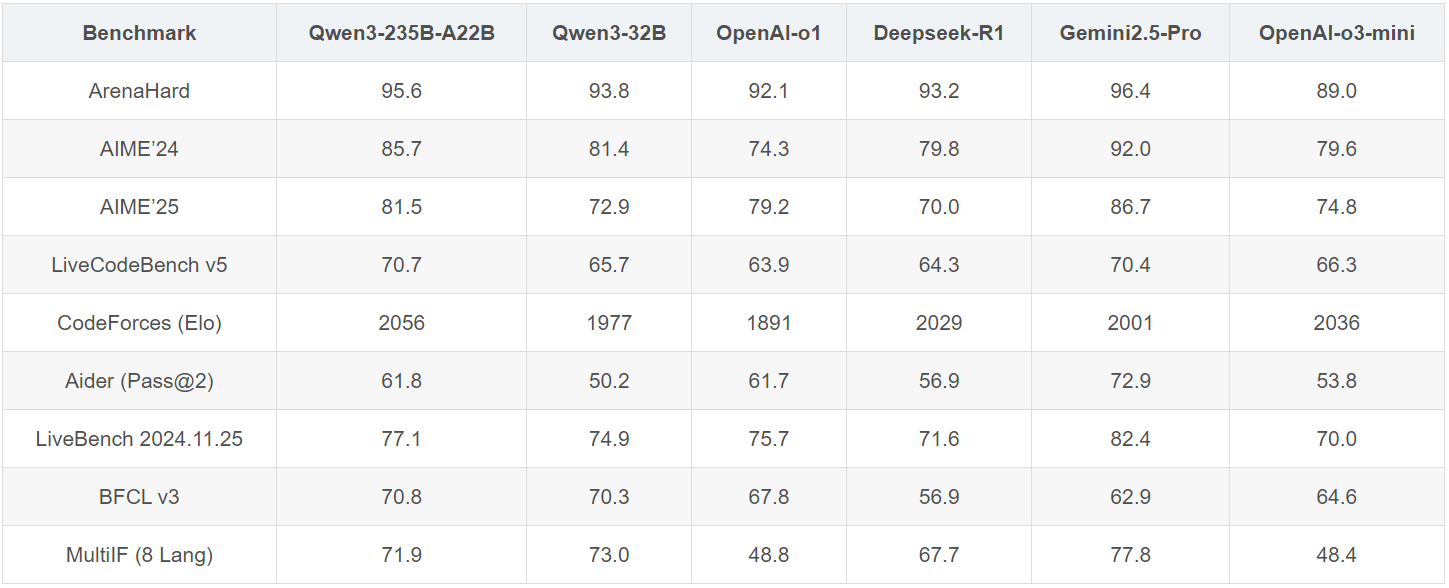
Qwen3与主流模型性能对比
通义千问 Qwen-2.5-VL系列
旗舰版Qwen2.5-VL-72B在13项权威评测中夺得视觉理解冠军,在包括大学水平的问答、数学、文档理解、视觉问答、视频理解和视觉智能体方面表现出色,全面超越GPT-4o与Claude3.5。
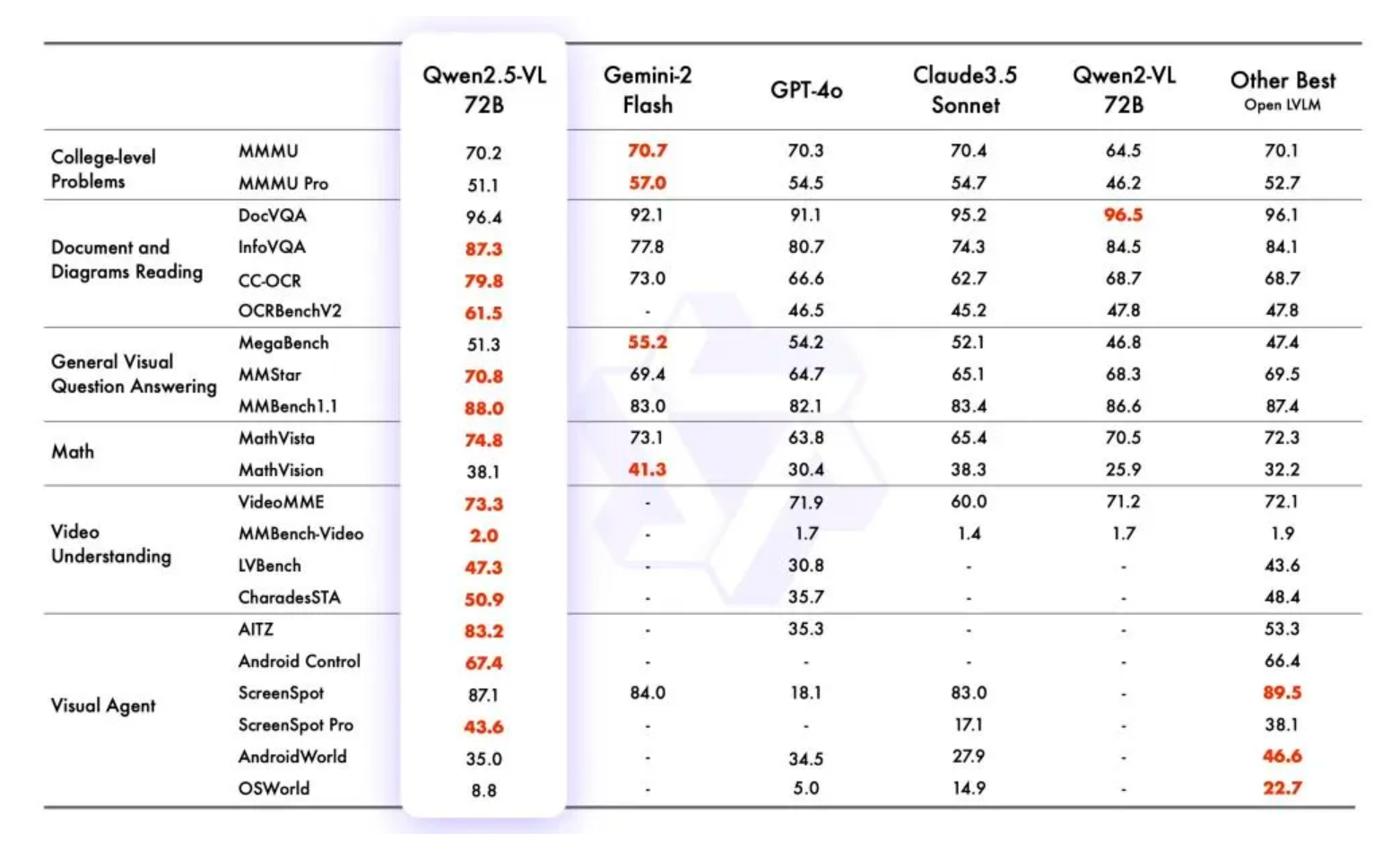
Qwen2.5-VL-72B 13项权威评测
通义万相Wanx-V2系列
具备分析图片内容并生成创意描述的能力,还可极速生成细节丰富的图像,生成效率高。在艺术创作、影视概念设计、质感人像、广告设计等场景中表现出色。

Flux-dev
由Black Forest Labs开源,参数规模达12B,在美学评分ELO上超越SD3和MJ6,擅长图片修复与风格转换,支持高分辨率图像生成与逼真人体解剖学细节。
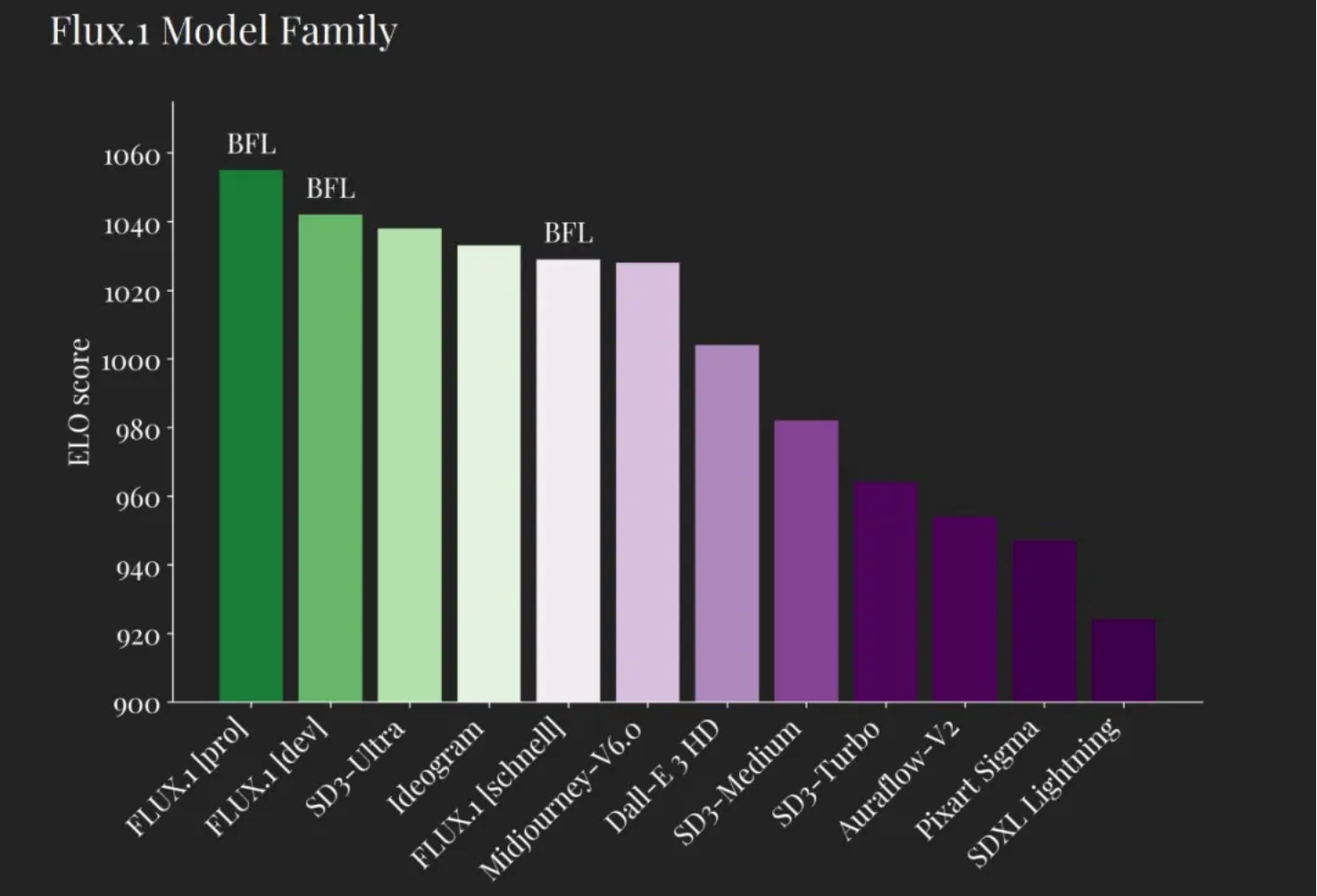
美学评分ELO
以下,我们基于通义千问Qwen系列模型进行简单测试:
图像识别
下图示例中,我们拼凑了16张相似的人眼较难区分的面包和小狗图片,借助OneThingAI平台的Qwen-2.5-VL系列模型来识别并按顺序标记图片类型。结果显示,无论是面包还是小狗,模型都能精确地区分和识别。

在专业领域,Qwen-2.5-VL系列模型还可对医学影像进行智能分析并提供决策参考。以鼻窦炎CT影像为例,模型能够精准识别鼻窦区域的黏膜厚度、窦腔积液、骨质结构改变等特征,为临床诊断提供量化分析依据。

文字识别与理解
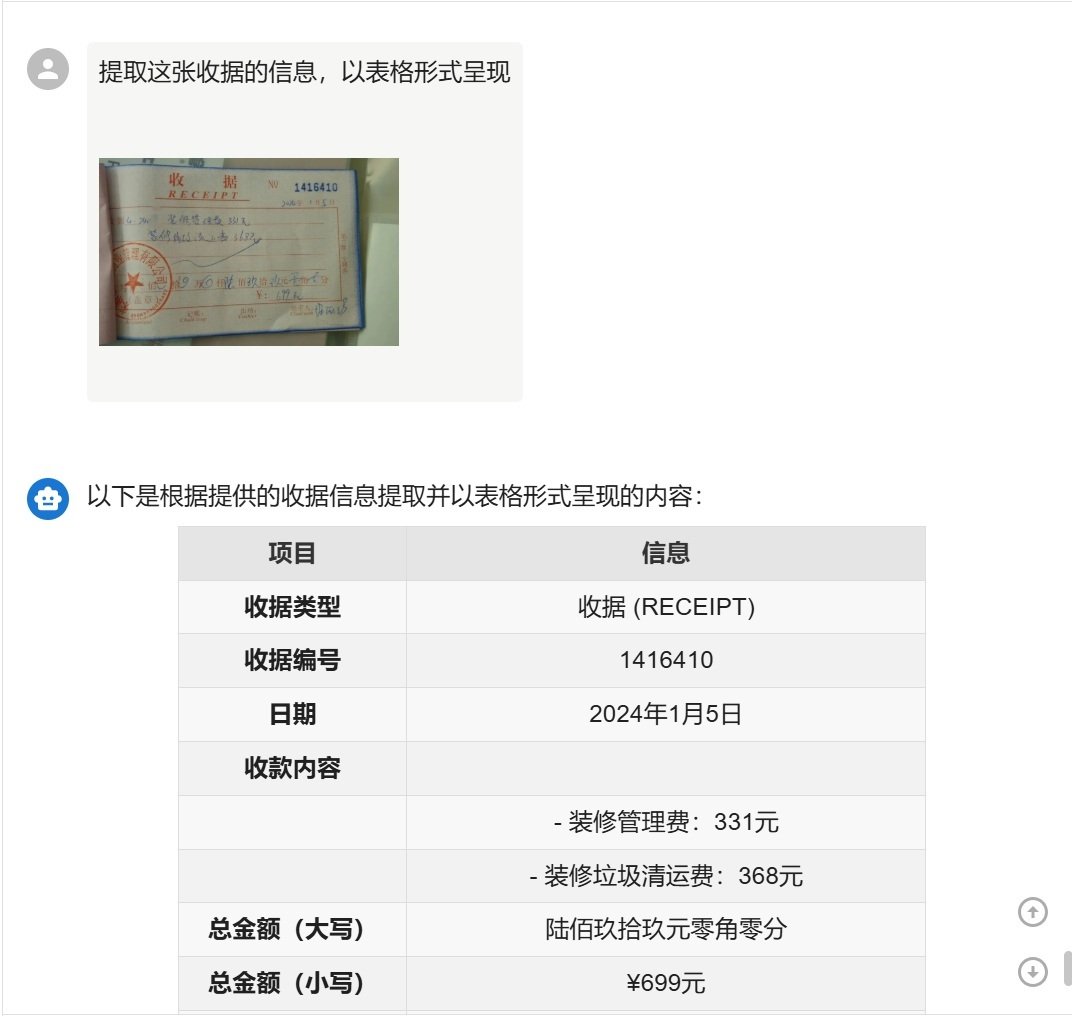
Qwen-2.5-VL系列模型具备国内领先的图像识别能力,比普通的文件扫描和OCR识别软件更加准确,例如收据单/快递单等潦草的手写内容都可以准确识别。
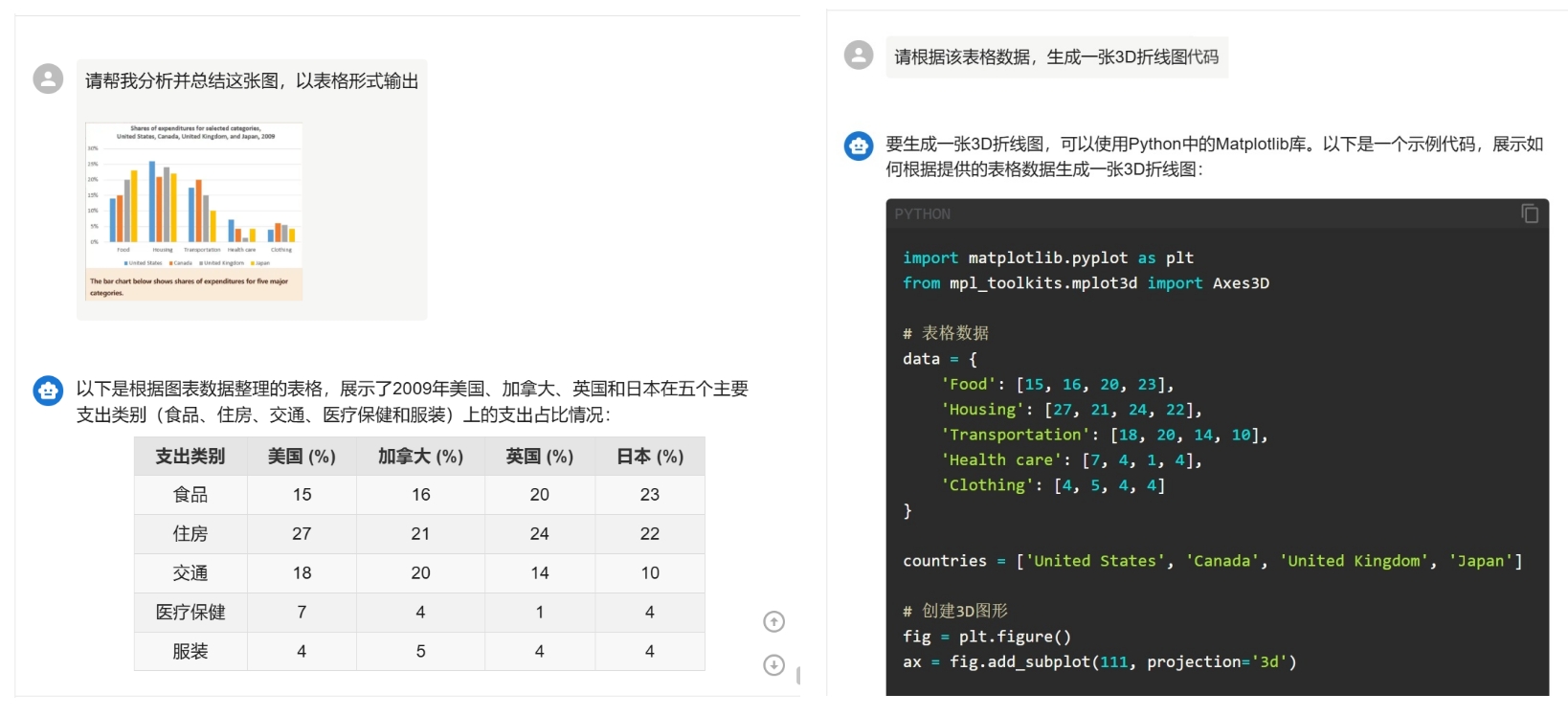
此外,Qwen3模型还支持多语言理解,能精准识别柱状图中美国、加拿大、英国、日本在食品、住房等5类支出的占比数值并输出结构化数据 ,同时基于结构化数据生成演示代码。