网心算力云上线Qwen3-Next:用十分之一成本,实现十倍性能
日前,通义千问新一代模型架构 Qwen3-Next 正式发布,其核心突破聚焦“成本 - 效率”双重维度:训练端,Base 模型成本被压缩至 Qwen3-32B 的 1/10 以下;推理端,上下文吞吐量较 Qwen3-32B 增幅超 10 倍,真正实现了极致的训练和推理性价比。
图 | Qwen3-Next架构系列模型
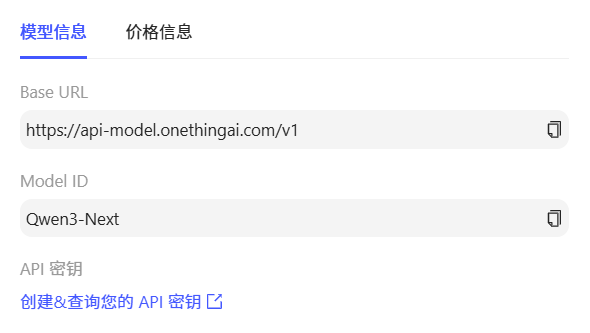
目前,Qwen3-Next架构系列模型已上线网心算力云平台,开发者们可直接调用平台提供的API服务,为自己的业务降本增效。
模型介绍
据悉,为了在长上下文和大参数场景下进一步提升训练与推理效率,通义千问团队设计了全新的模型架构Qwen3-Next,新架构对混合注意力机制、高稀疏性MoE、训练方法等进行了大幅度创新。
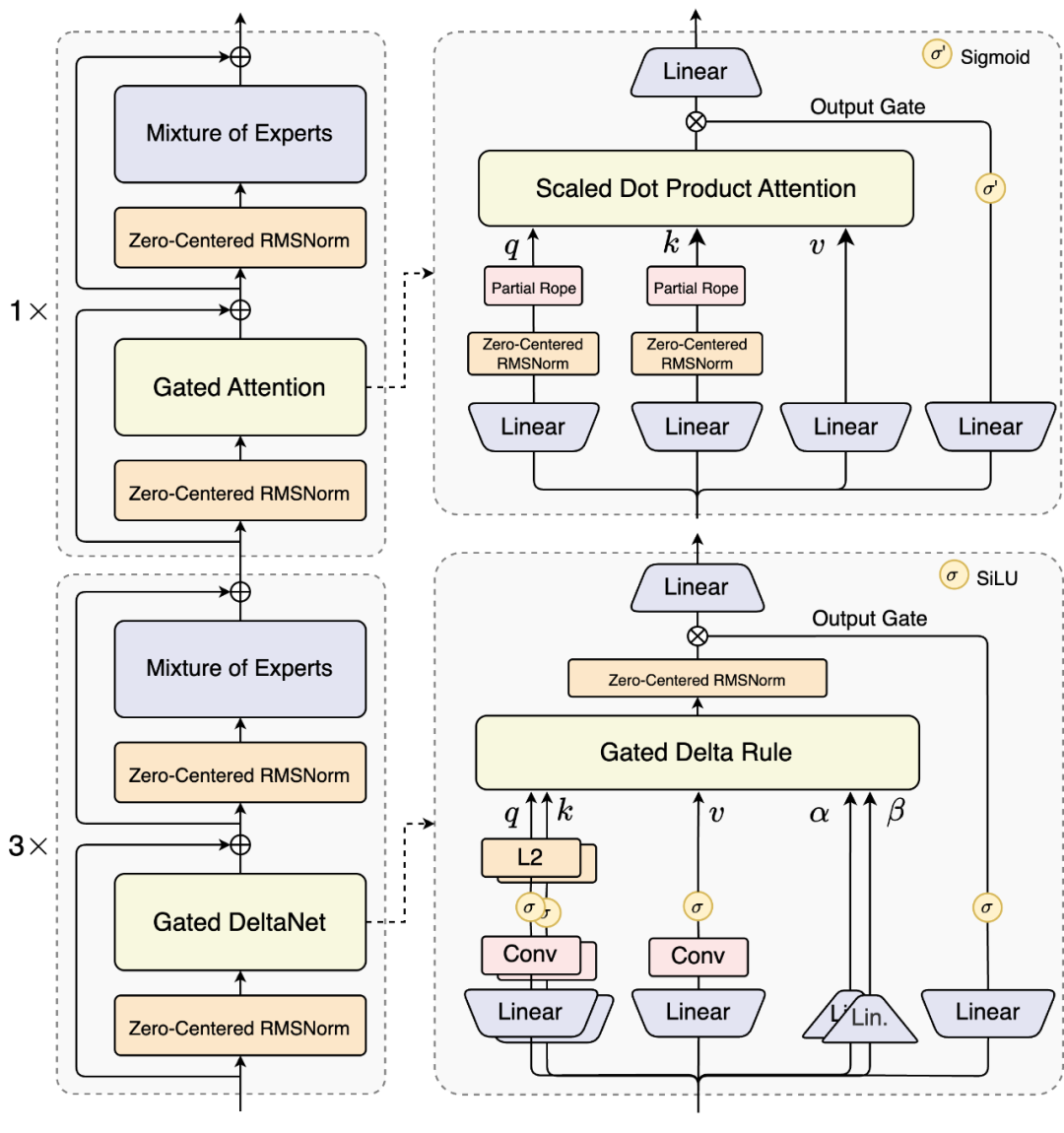
图 | Qwen3-Next模型结构示意图
得益于创新的混合模型架构,Qwen3-Next-80B-A3B(Instruct)模型和推理(Thinking)两款模型也陆续发布并开源,二者在推理效率上展现出显著优势。具体来说:
✅ Qwen3-Next-80B-A3B-Instruct
基于Qwen3新一代非思考开源模型,较上一版本Qwen3-235B-A22B-Instruct-2507中文文本理解能力更佳、逻辑推理能力更强、文本生成类任务表现更好。甚至在包含通用知识、数学推理等核心测评中全面超越了 SOTA 密集模型 Qwen3-32B。
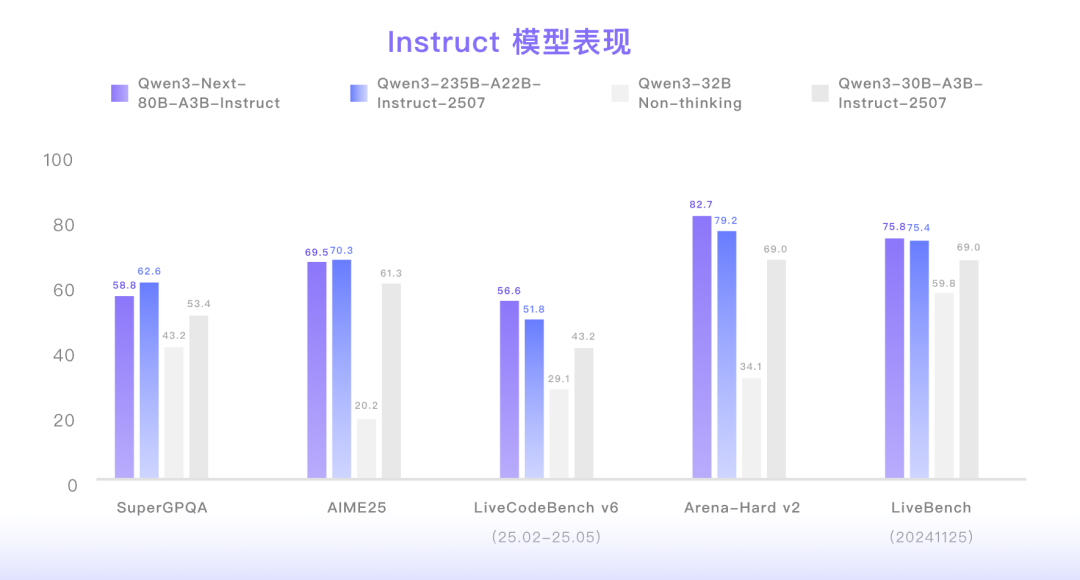
图 | Instruct 模型基准测试
在文本类生成任务中,我们让模型模仿李白的风格围绕“人工智能”作一首七言四句诗词。从生成结果上看,两首诗皆以李白式的豪放浪漫为底色,左诗借“星斗落瑶台”的奇幻想象,右诗凭“不羡飞仙纳九霄”的傲岸豪情,把 AI科技质感融入唐诗韵律,读起来既有古人气韵,又能感觉到 AI的“浪漫狂劲儿”。
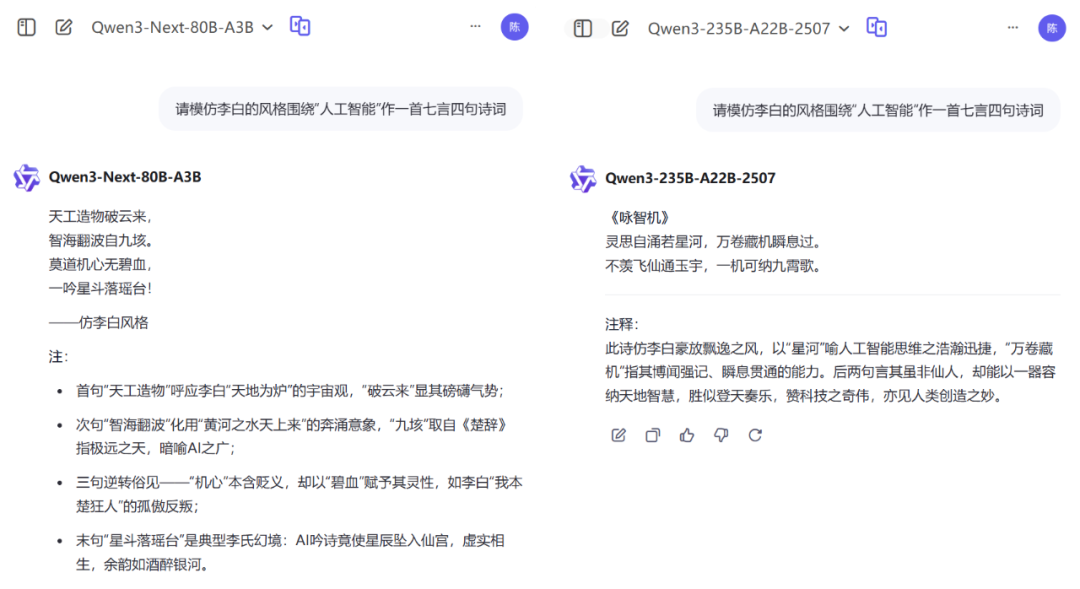
图 | 模型文本生成表现
✅ Qwen3-Next-80B-A3B-Thinking
基于Qwen3新一代思考开源模型,相较上一版本Qwen3-235B-A22B-Thinking-2507指令遵循能力有提升、模型总结回复更加精简。其在数学推理评测中以 87.8 分全面超越了 Gemini2.5-Flash-Thinking,而达到如此高水平的模型性能,仅需激活 Qwen3-Next 总参数 80B 中的 3B。
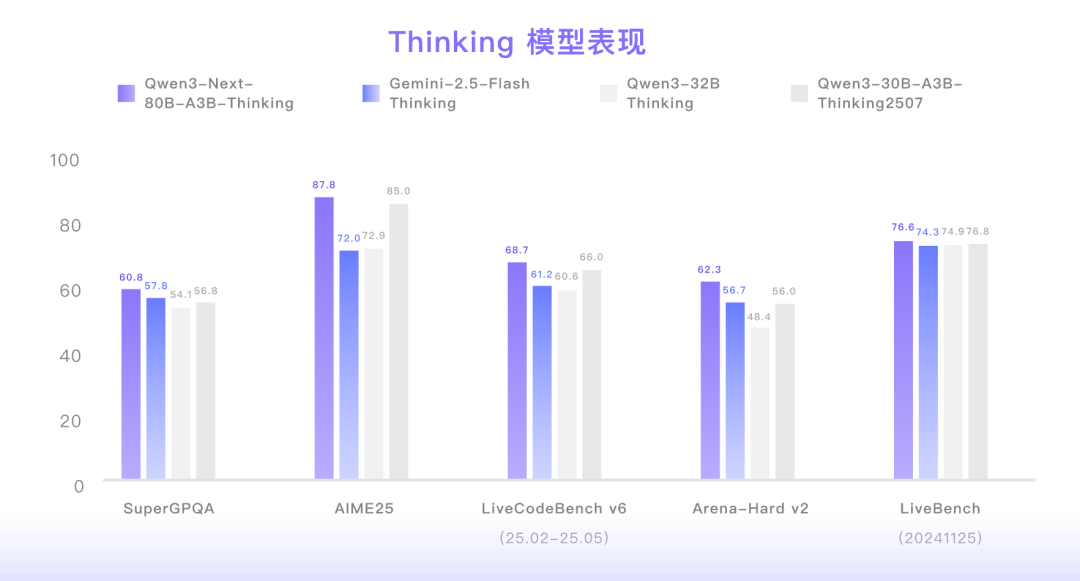
图 | Thinking 模型基准测试
在应对清华北大奥数题目时,Qwen3-Next-80B-A3B(Thinking)与上一代 Qwen3-235B-A22B-Thinking-2507 的表现旗鼓相当,尽管二者解题思路存在差异,但都清晰推导解题过程并给出了正确答案。
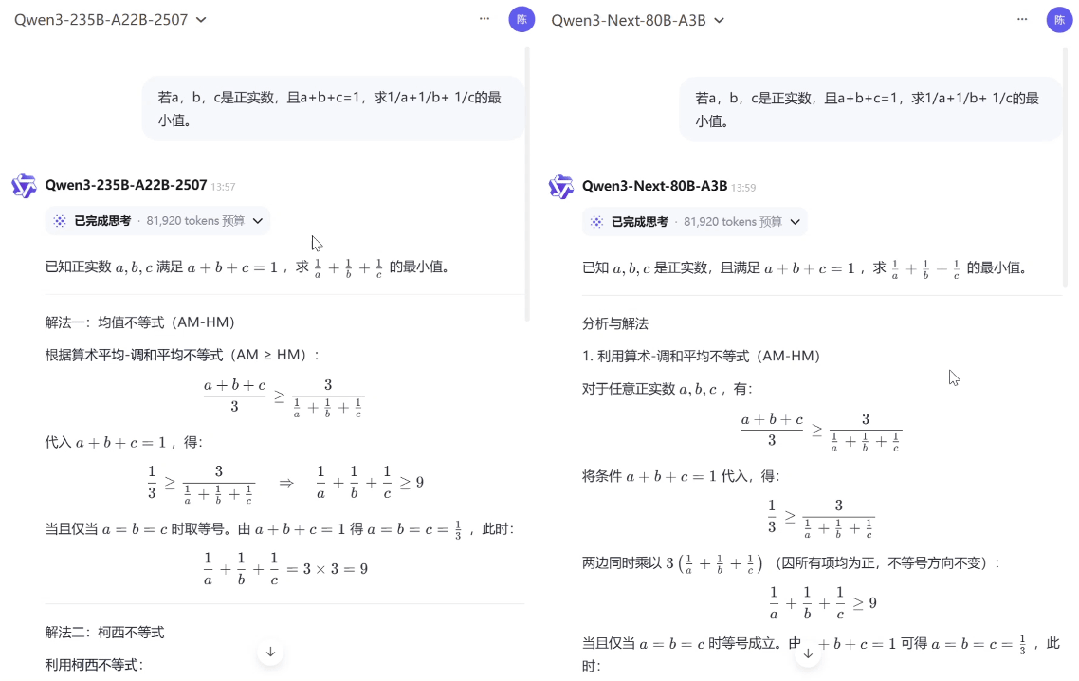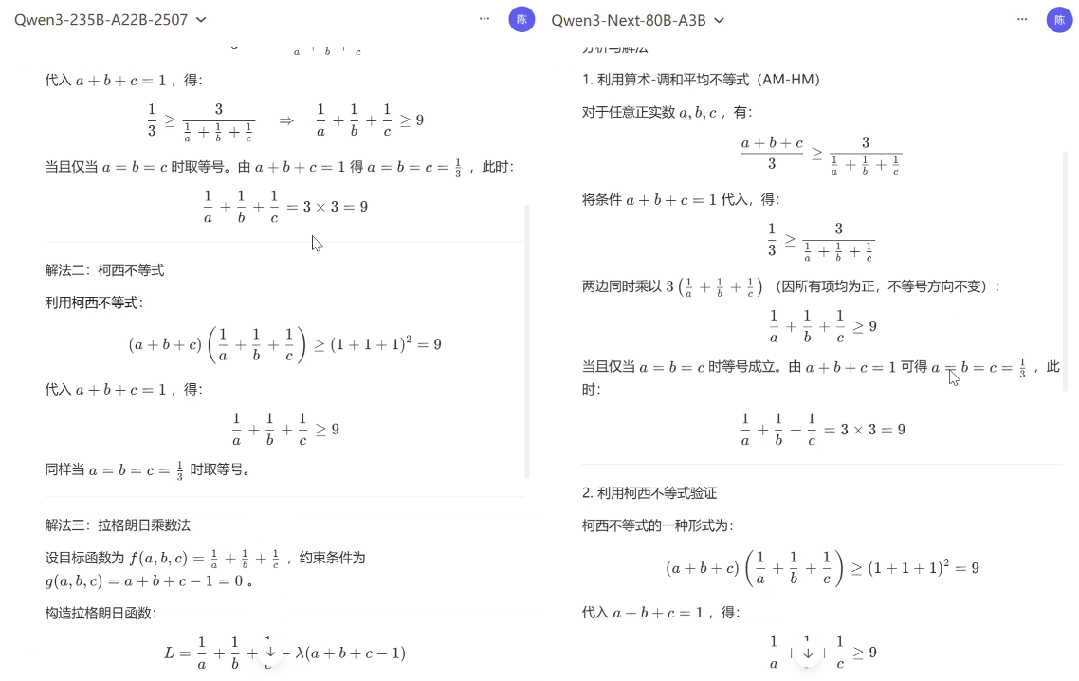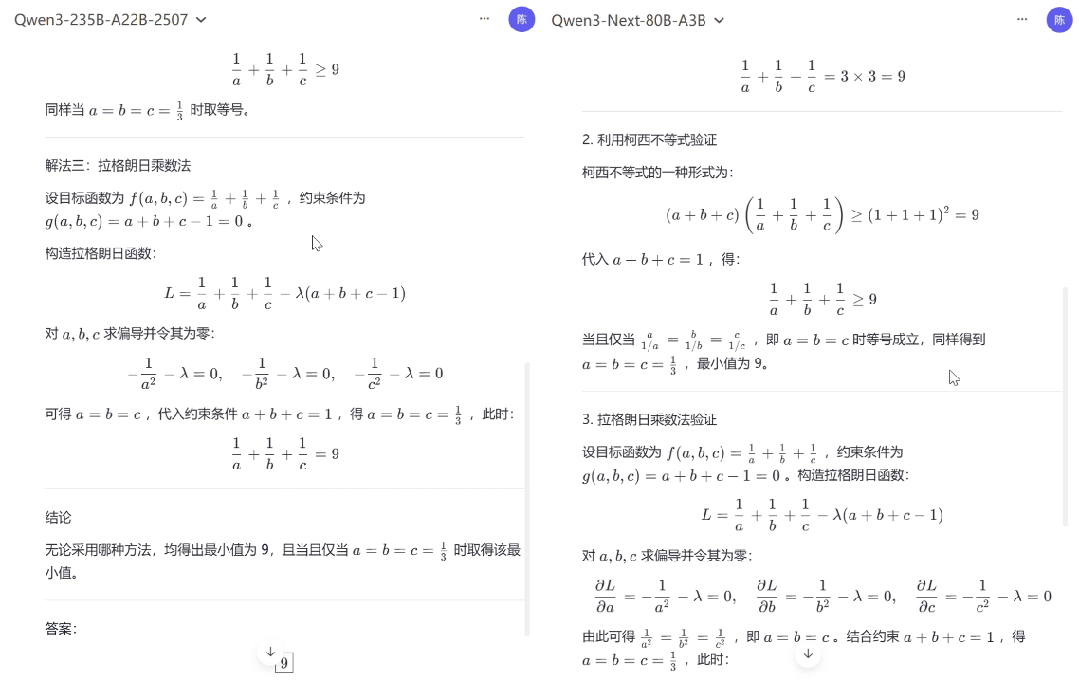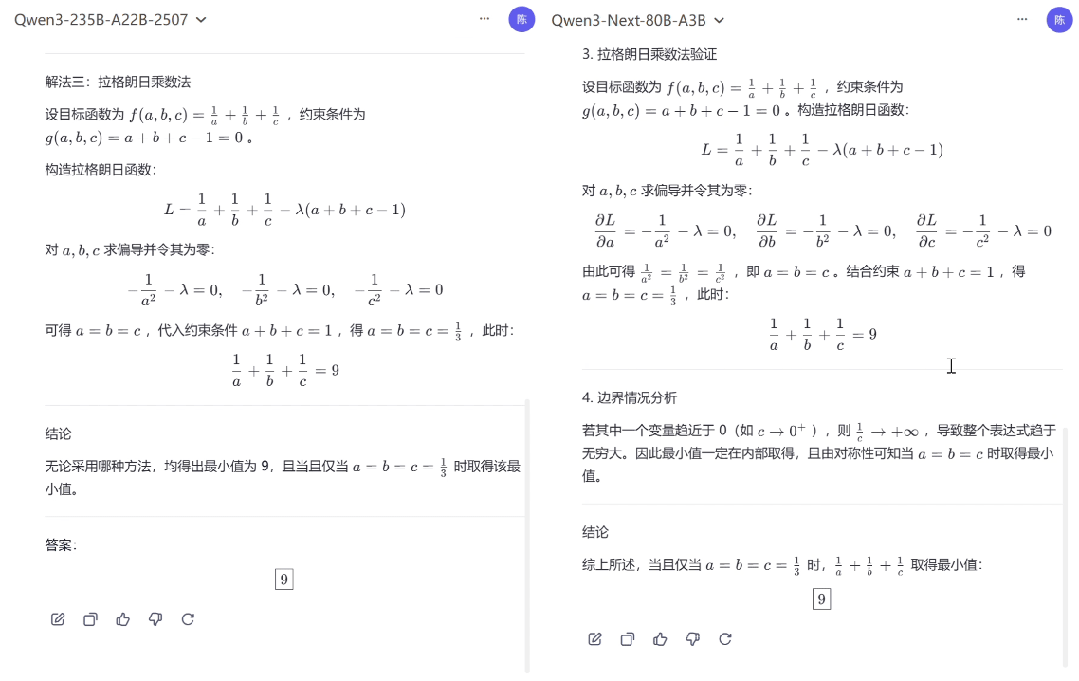
图 | 模型数学推理能力
模型接入
目前,网心算力云已接入通义千问Qwen3-Next系列大模型,助力用户和开发者加速AI应用的开发与落地。
步骤一:访问网心算力云官网,完成新用户注册。(新人注册立得5元代金券,学生认证&企业实名可得20元代金券)

步骤二:获取开发者密钥。登录OneThingAI平台,进入账户管理,选择「API密钥」自主创建。(通过平台密钥可与第三方建立通信,拉取平台提供的模型API列表)
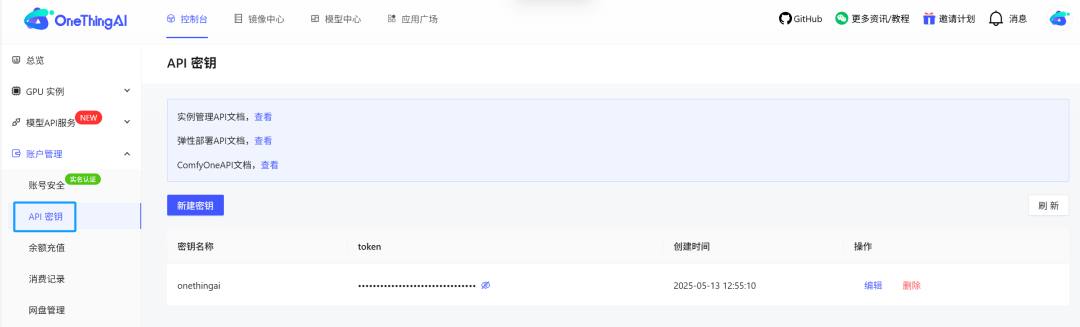
步骤三:OneThingAI平台提供curl、Python、Node.js三种技术方案,以便快速接入模型Qwen3-Next,满足多样化开发场景及开发者使用习惯。