网心算力云上线通义万相Wan2.2-S2V
通义万相重磅开源 —— 全新音频驱动视频模型Wan2.2-S2V超实用!仅需一张图片和一段音频,即可生成面部表情自然、口型匹配、肢体丝滑的电影级数字人视频,还支持分钟级时长,不管是数字人直播还是影视制作,效率直接拉满!
目前,Wan2.2-S2V模型已在网心算力云ComfyUI_v.0.0.86版本中全面支持。
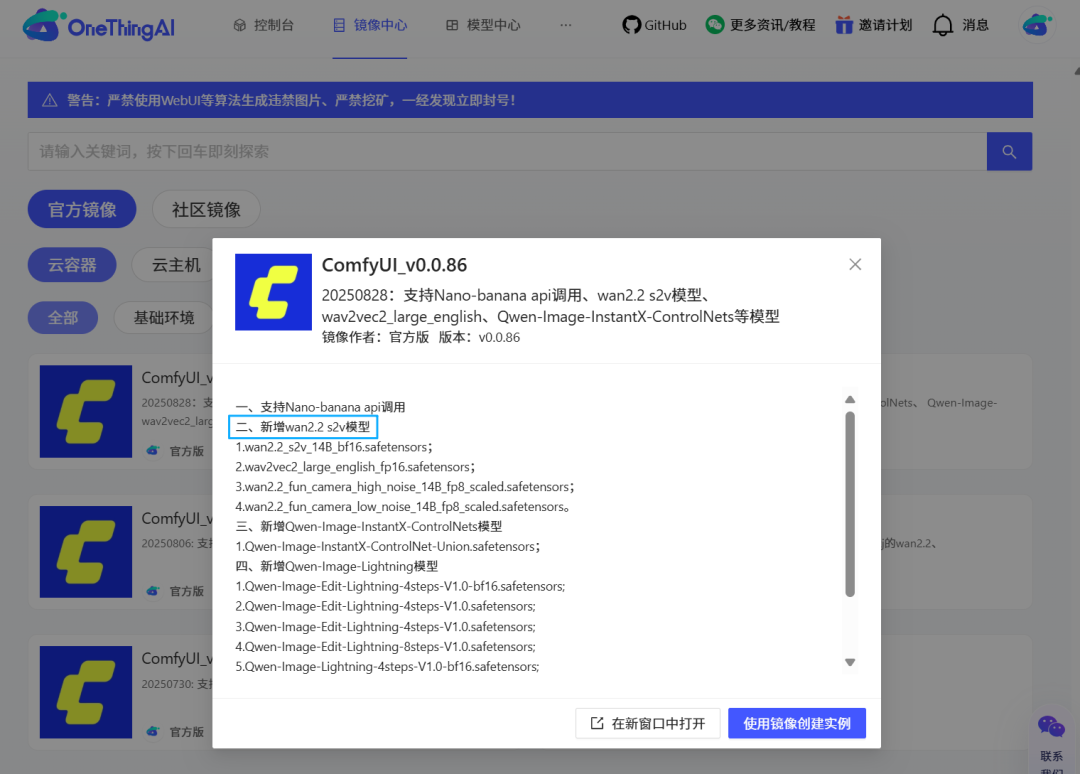
图 | 网心算力云镜像中心
模型介绍
据官方透露,此次开源的Wan2.2-S2V可不是只动动嘴皮子的普通模型:手势、表情、姿态都能灵活联动,且完美适配卡通、动物等风格化形象,甚至能稳定生成分钟级长视频,实力相当全面。其在更深层的架构设计层面,还暗藏了不少创新亮点:
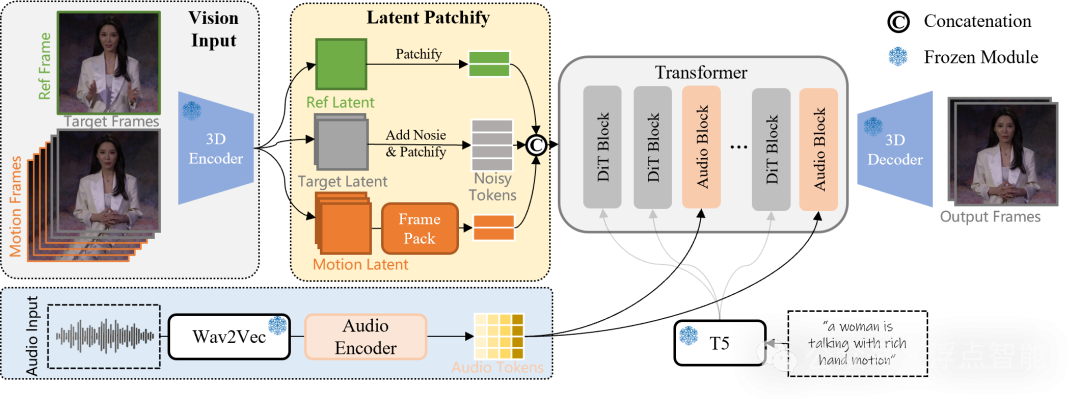
图 | 音频驱动的视频模型架构
✅ 融合文本引导的全局运动控制和音频驱动的细粒度局部运动,实现复杂场景的音频驱动视频生成;
✅ 引入 AdaIN 和 CrossAttention 控制机制,实现了更准确更动态的音频控制效果;
✅ 通过层次化帧压缩技术,大幅降低历史帧 Token 数量,实现了稳定的长视频生成效果;
✅ 构建了超60万个片段的音视频数据集,通过混合并行训练、全参数化训练充分挖掘模型性能;
✅ 通过多分辨率训练和推理,支持生成不同分辨率场景视频(如竖屏短视频、横屏影视剧,提供480P与720P两档分辨率的视频规格);
✅ 支持文本控制视频画面实现镜头运动、角色轨迹和实体间互动,让视频效果更加丰富。
模型部署
1)登录网心算力云,打开镜像中心并选择“ComfyUl_v0.0.86”快速创建实例。
2)选择合适的配置,点击创建并开机。
3)运行实例,找到对应工作流,即可开始测试。
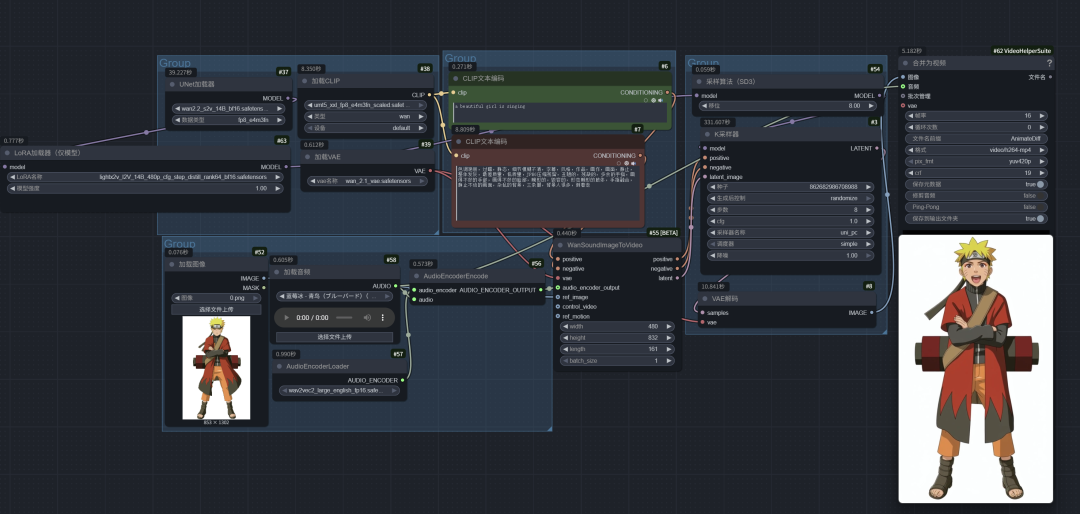
模型表现
据官方介绍,Wan2.2-S2V模型在数字人直播、影视短剧创作、壁纸设计等领域表现不俗。以下是模型生成的素材,大家看看效果如何:

视频 | 热血动漫

视频 | 悬疑短剧

视频 | 抽象演唱

视频 | 动物场景

视频 | 卡通3D场景